La haute disponibilité vise à garantir qu'un service web reste accessible même en cas de panne. Pour cela, on supprime les points uniques de défaillance par la redondance à tous les niveaux.
Qu'est-ce que la haute disponibilité
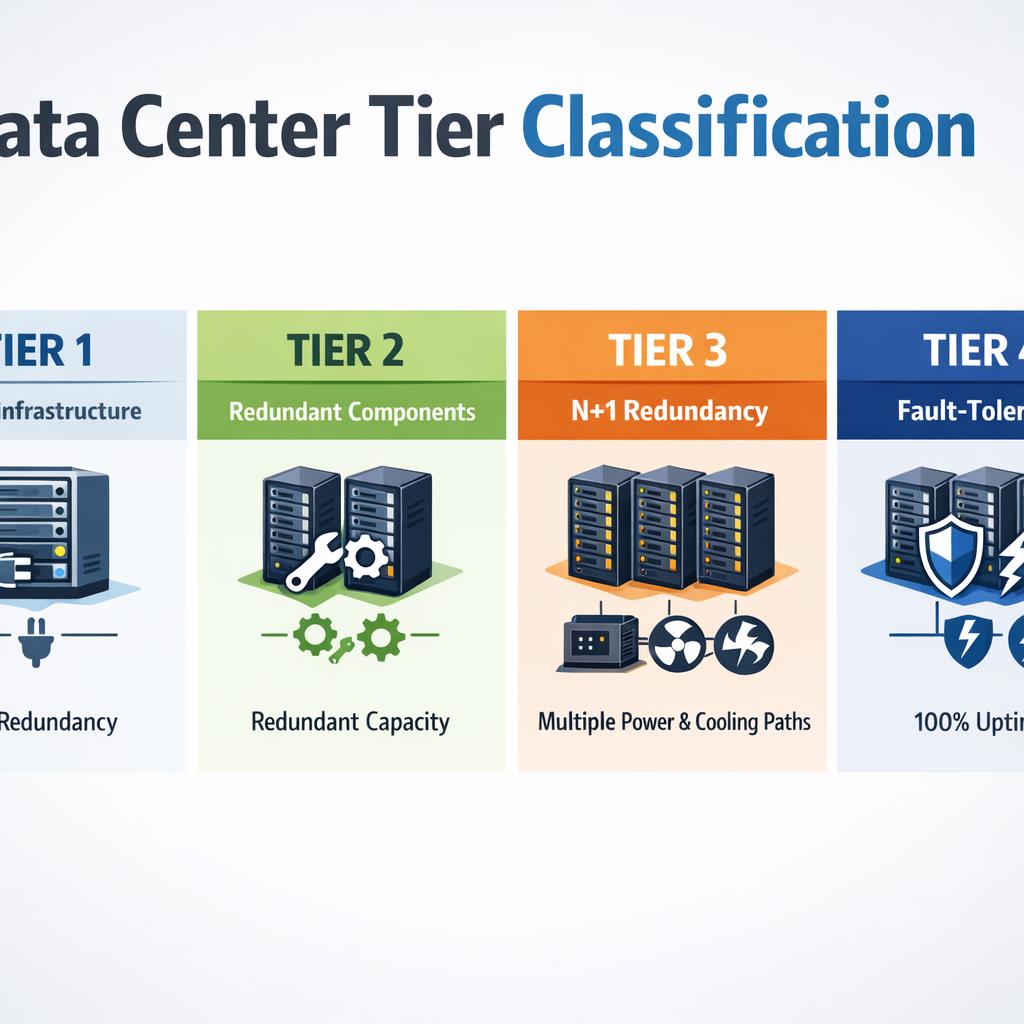
La haute disponibilité (HA) est la capacité d'un système à rester accessible en toutes circonstances. Elle se mesure en pourcentage : 99 % équivaut à 3 j 15 h d'indisponibilité par an, 99,9 % à 8 h 45 min, 99,99 % à 52 minutes, 99,999 % à 5 minutes. Chaque « neuf » supplémentaire coûte exponentiellement plus cher.
Le principe de redondance
Tout composant critique doit être dupliqué. Deux alimentations électriques, deux fournisseurs Internet, deux serveurs, deux datacenters. En cas de défaillance d'un élément, le second prend le relais sans interruption pour l'utilisateur. Le coût double grosso modo, mais la disponibilité grimpe fortement.
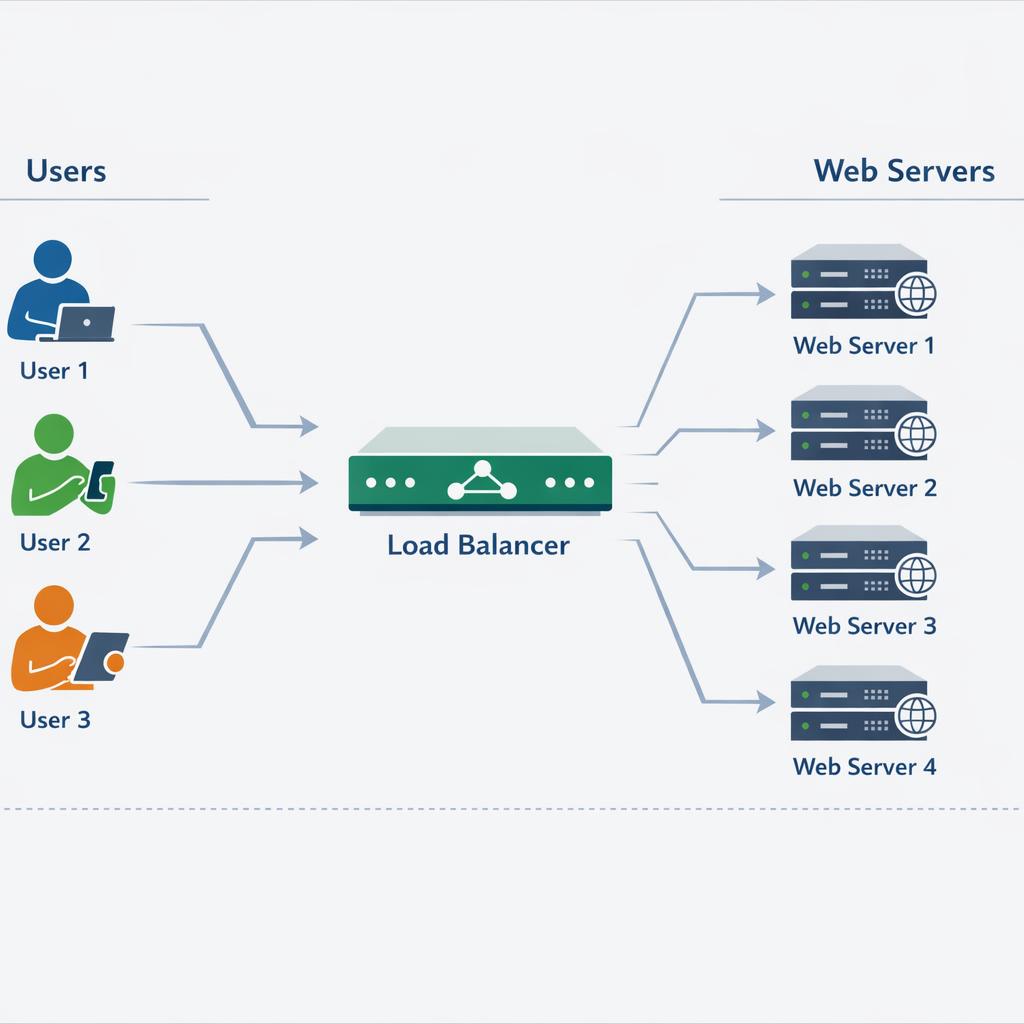
Le load balancing
Un répartiteur de charge (load balancer) distribue les requêtes entrantes entre plusieurs serveurs web identiques. Si un serveur tombe, les autres continuent à servir les utilisateurs. En prime, la charge est répartie et les performances globales augmentent. Pour approfondir, consultez notre article load balancing avec HAProxy et Nginx.
Le failover automatique
En configuration active-passive, un serveur principal gère le trafic tandis qu'un serveur secondaire est en veille. En cas de panne, le secondaire prend le relais automatiquement en quelques secondes. En configuration active-active, tous les serveurs partagent la charge, la panne de l'un ne fait que réduire temporairement la capacité. Voir notre article failover et cluster actif-passif.
La réplication de données
Les bases de données critiques doivent être répliquées en temps réel sur plusieurs serveurs. MySQL, PostgreSQL, MongoDB, Redis offrent tous des mécanismes de réplication maître-esclave ou multi-maître. Le choix dépend du compromis entre cohérence et latence.
La répartition géographique
Pour se protéger contre une catastrophe (incendie, inondation, sinistre électrique généralisé), répartir l'infrastructure entre plusieurs datacenters éloignés. Les grands providers cloud proposent nativement cette répartition. Coût accru mais résilience exceptionnelle.
Les SLA et les disponibilités contractuelles
Les hébergeurs s'engagent contractuellement sur des niveaux de disponibilité. Lire le SLA avec attention : certains définissent la disponibilité de manière restrictive (seules les pannes complètes comptent, pas les dégradations). Voir notre article SLA et disponibilité à 99,99 %.
Tester les mécanismes
Un système de haute disponibilité non testé n'est pas fiable. Des exercices réguliers (chaos engineering : couper volontairement un serveur) révèlent les faiblesses avant qu'une vraie panne ne les expose. Netflix a popularisé cette approche avec Chaos Monkey.
Où commencer
Pour un petit projet, la haute disponibilité complète est disproportionnée. Commencer par : doubler les backups, mettre un CDN devant le site, vérifier les points critiques (base de données, réseau). La HA se construit progressivement selon la criticité. Pour une vue d'ensemble, retrouvez notre guide complet de l'hébergement.